Masked Temporal Interpolation Diffusion for Procedure Planning in Instructional Videos
Jan 1, 1970·, ,·
0 min read
,·
0 min read
Yufan Zhou
Lingshuai Lin
Junqi Jing(荆浚淇)
Et Al.
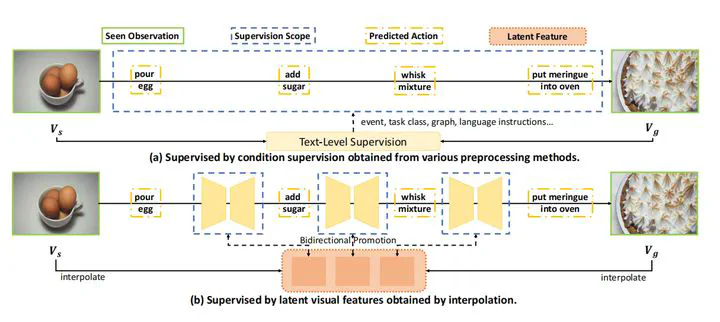 Image credit: MTID project.
Image credit: MTID project.Abstract
We propose MTID, a novel diffusion-based model for procedure planning in instructional videos—predicting coherent action sequences given the start and end observations. Unlike previous works that rely heavily on text-level supervision, MTID introduces a latent space temporal interpolation module to synthesize richer mid-state visual features, improving temporal reasoning. We further design an action-aware mask projection and a task-adaptive masked proximity loss, enabling the model to focus on task-relevant, temporally coherent actions. Our method achieves state-of-the-art performance on multiple benchmarks.
Type
Publication
In International Conference on Learning Representations (ICLR) 2025